No industry will be spared.
The pharmaceutical business is perhaps the only industry on the planet, where to get the product from idea to market the company needs to spend about a decade, several billion dollars, and there is about 90% chance of failure. It is very different from the IT business, where only the paranoid survive but a business where executives need to plan decades ahead and execute. So when the revolution in artificial intelligence fueled by credible advances in deep learning hit in 2013–2014, the pharmaceutical industry executives got interested but did not immediately jump on the bandwagon. Many pharmaceutical companies started investing heavily in internal data science R&D but without a coordinated strategy it looked more like re-branding exercise with the many heads of data science, digital, and AI in one organization and often in one department. And while some of the pharmaceutical companies invested in AI startups no sizable acquisitions were made to date. Most discussions with AI startups started with “show me a clinical asset in Phase III where you identified a target and generated a molecule using AI?” or “how are you different from a myriad of other AI startups?” often coming from the newly-minted heads of data science strategy who, in theory, need to know the market.
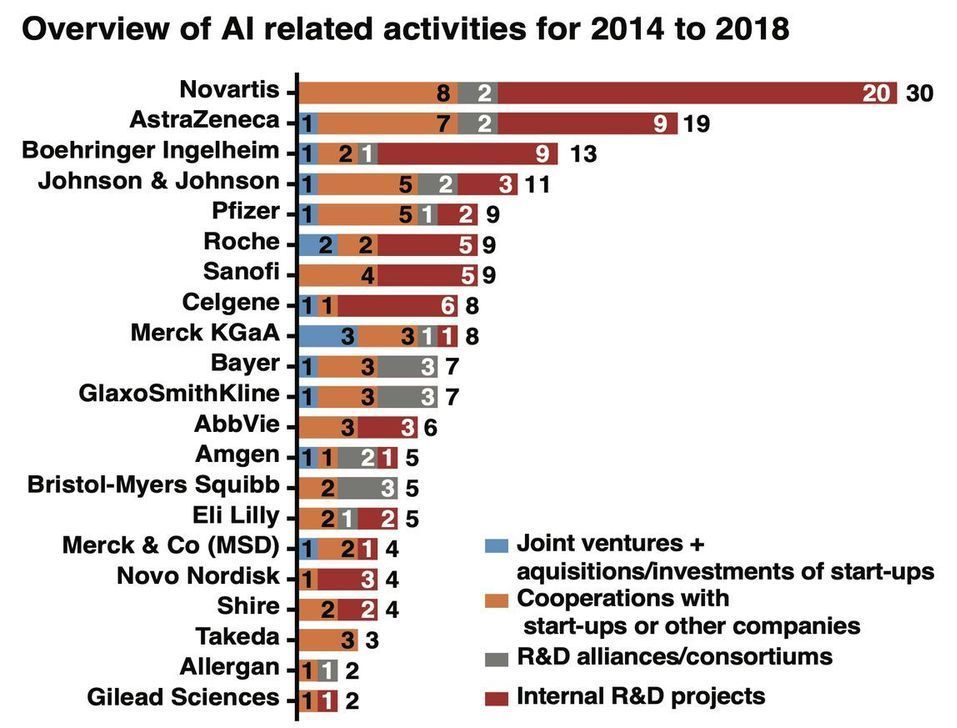
However, some of the pharmaceutical companies managed to demonstrate very impressive results in the individual segments of drug discovery and development. For example, around 2018 AstraZeneca started publishing in generative chemistry and by 2019 published several impressive papers that were noticed by the community. Several other pharmaceutical companies demonstrated impressive internal modules and Eli Lilly built an impressive AI-powered robotics lab in cooperation with a startup.
However, it was not possible to get a comprehensive overview and comparison of the major pharmaceutical companies that claimed to be doing AI research and utilizing big data in preclinical and clinical development until now. On June 15th, one article titled “The upside of being a digital pharma player” got accepted and quietly went online in a reputable peer-reviewed industry journal Drug Discovery Today. I got notified about the article by Google Scholar because it referenced several of our papers. I was about to discard the article as just another industry perspective but then I looked at the author list and saw a group of heavy-hitting academics, industry executives, and consultants: Alexander Schuhmacher from Reutlingen University, Alexander Gatto from Sony, Markus Hinder from Novartis, Michael Kuss from PricewaterhouseCoopers, and Oliver Gassmann from University of St. Gallen.