Jan 9, 2023
Apple Maps teams up with parking app SpotHero to give users access to 8K parking options
Posted by Gemechu Taye in categories: mapping, mobile phones
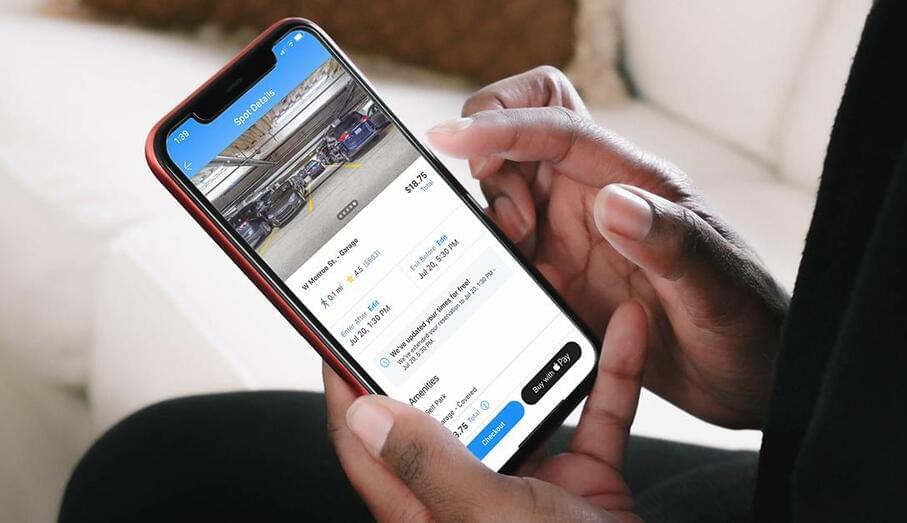
Apple Maps launched a new parking feature that provides users with parking options and availability near a specific destination. In partnership with the digital parking reservation platform, SpotHero, Apple Maps users across the U.S. and Canada can now get parking information for over 8,000 locations.
To use the new feature, launched late last week, iPhone and Mac users can search for a destination in the Apple Maps app and then select “More” and “Parking.” They’re then directed to the SpotHero website without leaving Apple Maps. Users can search for nearby parking and reserve a space using SpotHero’s secure payment options, the parking platform claims.
SpotHero also allows users to filter their search by date and time as well as parking spots with EV charging, wheelchair accessibility, valet services and more.