Language models (LMs) are a cornerstone of artificial intelligence research, focusing on the ability to understand and generate human language. Researchers aim to enhance these models to perform various complex tasks, including natural language processing, translation, and creative writing. This field examines how LMs learn, adapt, and scale their capabilities with increasing computational resources. Understanding these scaling behaviors is essential for predicting future capabilities and optimizing the resources required for training and deploying these models.
The primary challenge in language model research is understanding how model performance scales with the amount of computational power and data used during training. This scaling is crucial for predicting future capabilities and optimizing resource use. Traditional methods require extensive training across multiple scales, which is computationally expensive and time-consuming. This creates a significant barrier for many researchers and engineers who need to understand these relationships to improve model development and application.
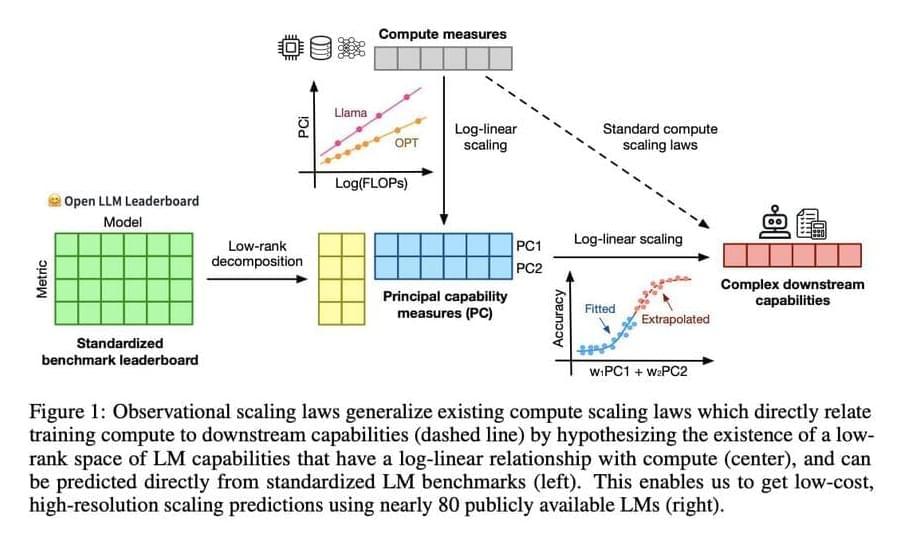
Existing research includes various frameworks and models for understanding language model performance. Notable among these are compute scaling laws, which analyze the relationship between computational resources and model capabilities. Tools like the Open LLM Leaderboard, LM Eval Harness, and benchmarks like MMLU, ARC-C, and HellaSwag are commonly used. Moreover, models such as LLaMA, GPT-Neo, and BLOOM provide diverse examples of how scaling laws can be practiced. These frameworks and benchmarks help researchers evaluate and optimize language model performance across different computational scales and tasks.








Leave a reply