Despite being almost a year old, this blog by Chip Huyen is still a great read for getting into fine-tuning LLMs.
This article covers everything you need to know about Reinforcement Learning from Human Feedback (RLHF).
#AI #ReinforcementLearning
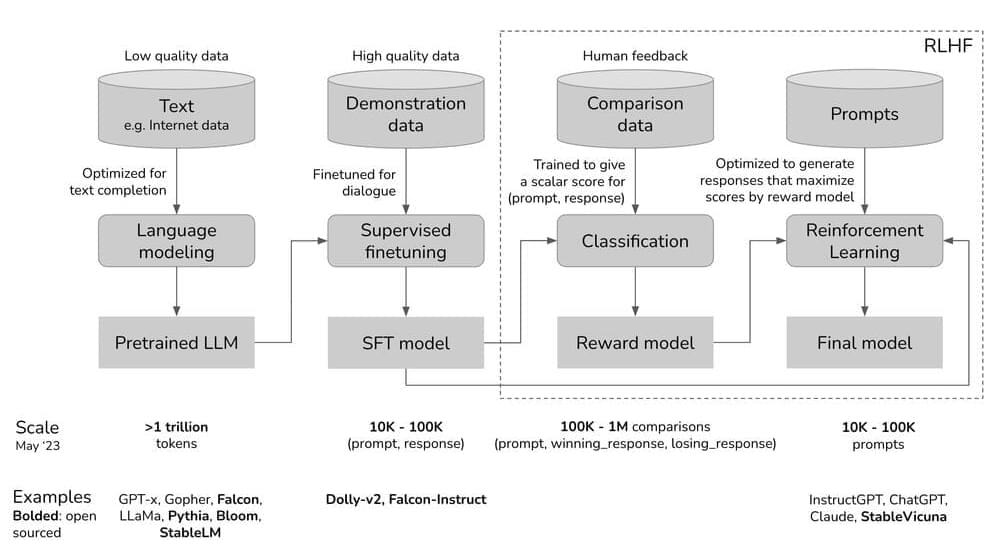
A narrative that is often glossed over in the demo frenzy is about the incredible technical creativity that went into making models like ChatGPT work. One such cool idea is RLHF: incorporating reinforcement learning and human feedback into NLP. This post discusses the three phases of training ChatGPT and where RLHF fits in. For each phase of ChatGPT development, I’ll discuss the goal for that phase, the intuition for why this phase is needed, and the corresponding mathematical formulation for those who want to see more technical detail.









Comments are closed.