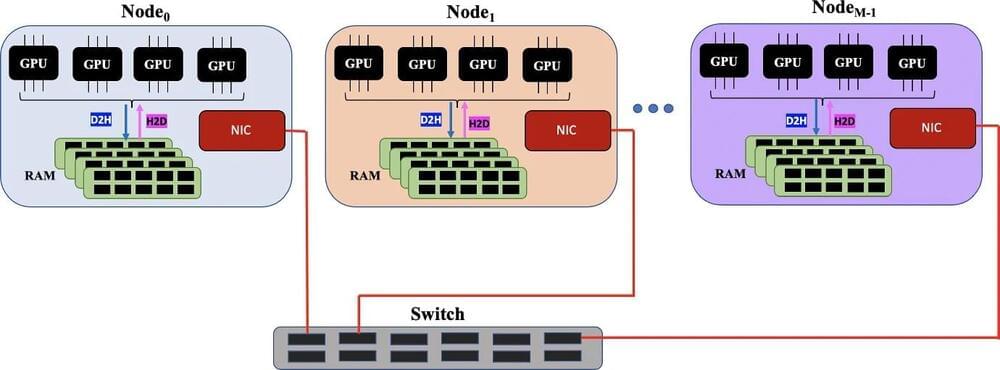
A machine-learning algorithm demonstrated the capability to process data that exceeds a computer’s available memory by identifying a massive data set’s key features and dividing them into manageable batches that don’t choke computer hardware. Developed at Los Alamos National Laboratory, the algorithm set a world record for factorizing huge data sets during a test run on Oak Ridge National Laboratory’s Summit, the world’s fifth-fastest supercomputer.
Equally efficient on laptops and supercomputers, the highly scalable algorithm solves hardware bottlenecks that prevent processing information from data-rich applications in cancer research, satellite imagery, social media networks, national security science and earthquake research, to name just a few.
“We developed an ‘out-of-memory’ implementation of the non-negative matrix factorization method that allows you to factorize larger data sets than previously possible on a given hardware,” said Ismael Boureima, a computational physicist at Los Alamos National Laboratory. Boureima is first author of the paper in The Journal of Supercomputing on the record-breaking algorithm.









Comments are closed.