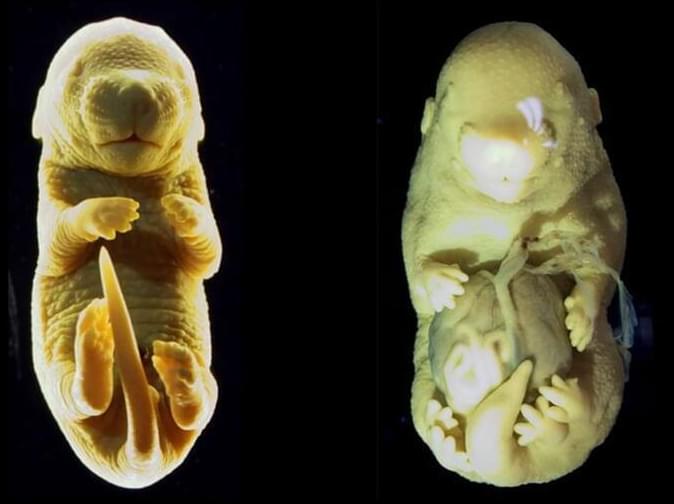
Apr 17, 2024
Paper page — MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Posted by Dan Breeden in category: futurism

Meta announces MA-LMM
Memory-augmented large multimodal model for long-term video understanding.
With the success of large language models (#LLMs), integrating the vision model into LLMs to build vision-language #foundation models has gained much more interest…